画像でボケる機械学習モデルでコロナ渦も笑ってクリスマスを迎えたい

この記事はKyoto University Advent Calendar 2020の記事の12/23日目の記事です。あと1週間で今年も終わってしまうのが実感ありません。
どらさんの京都の四季の記事では紹介されている写真がとにかく高画質で、季節によって変化する京都を楽しめました。
Emileさんの強化学習記事はActor-Criticの理論から結果の動画まで紹介されていて面白かったです。強化学習は実装したことがないので僕も今度何か作ってみたいです。
こんにちは k3ntと言います。京大の情報学研究科のM1で自然言語処理と画像を絡めたマルチメディア言語処理と呼ばれる分野の研究に取り組んでいます。 京大のアドベントカレンダーも残すところ3日となりました。
みなさん今年のクリスマスはどう過ごすのでしょうか(煽り)
今年も一人でクリスマスを過ごすみなさんが、一人でも笑って過ごせるように、画像でボケる機械学習モデルを今回は作っていきます。
ステップは2つだけなので簡単です。
(1) 大喜利サービスボケてからデータを頂いてくる。
(2) 画像キャプション生成モデルに用意したデータを突っ込んで学習させる。
はじめにコードのリンク貼っておきます。
→GitHub Code
本記事ではコードの解説はしないので、気になる方は是非参考にしてください。
データ用意
画像でボケるモデルを作る上で、まずは特定の画像に対するボケのお手本のようなものをコンピュータにたくさん学習させる必要があります。従って、画像とそれに対するボケの日本語文のペアを準備する必要があります。
ボケて は株式会社オモロキが運営している大喜利サイトで、ユーザーは「お題」として画像を投稿することができ、そのお題に対して他の複数のユーザーがテキストによる「ボケ」を投稿することで、ユーモアを笑い楽しむサービスです。

今回はこのサイトから約1.5万組(画像とボケテキスト)のデータを用意して学習させます。
画像キャプション生成
画像キャプション生成は、画像を入力として与えると画像の内容を説明する簡単なテキストを生成することを指します。
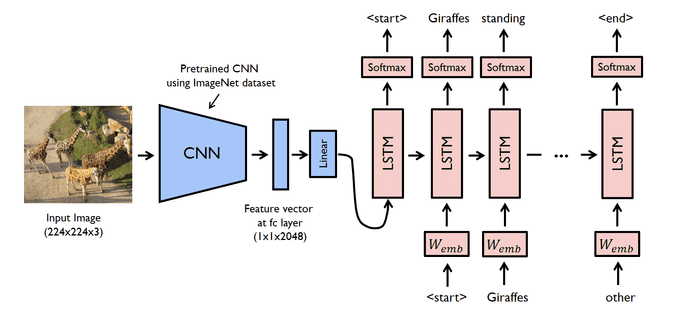
ImageNetで事前学習済みのCNNモデル(resnet18)から2048次元の特徴量を抽出し、これを時系列データを扱うことのできるRNNの一種であるLSTMに入力することで、テキストを生成するという仕組みになっています。損失関数にはソフトマックスエントロピーを用いて学習しており、DecoderとなるLSTMは1時刻前の隠れ状態を入力として、反復的に単語を出力してテキストを生成します。
画像キャプション生成技術は2014年のCVPRでGoogleが発表した “Show and Tell: A Neural Image Caption Generator”を皮切りに研究が進められており、自動運転や画面付きスマートスピーカーなど、適用先は多岐に渡っています。
今回はこちらのコード(github)を参考にモデルを組みました。
学習
学習には14,495のデータを使い、バッチサイズは128で50エポック回した時のlossが下がり切った時のパラメータの値をボケてモデル学習済みモデルとして保存しました。アドカレの期限に追われて必死でGPUをぶん回して50分ほどで学習は終了しました。
学習結果
学習に使わなかった画像を与えて、学習させたモデルにボケてもらいましょう。
-
大仏の写真
 モデルのボケ
モデルのボケ自粛しなさい
これは上手くぼけられてるのではないでしょうか。飛行機を摘んで止めているように見えるので納得です。
-
PCをいじる人の写真
 モデルのボケ
モデルのボケ逃げろ…!俺が動きを止められるのは1分が限界だ…
こちらは清原さんのtwitterの写真をお借りしたものです。ホワイトハッカーか何かでしょうか。
-
キャラクターのイラスト
 モデルのボケ
モデルのボケこのようなウーバーイーツがきたらヤバい奴と思ってくれて結構です
-
京都大学
 モデルのボケ
モデルのボケサザエさんエンディング体験・・・
-
石像
 モデルのボケ
モデルのボケくす玉がなかなか割れない
まとめ
今回はwebサービスボケてのデータを使って、画像でボケるモデルを実装しました。 アドカレのネタ用に急ピッチで回した雑な実験なので、色々とツッコミどころがある点はご容赦くださいmm
今回は簡単に定性的な評価を行いましたが、定量的評価も必要になると思います。しかし、ユーモアの評価は人によって価値観が異なるので、単純な数値で表現し切れない部分もあります。この評価の部分だけでも十分研究テーマにな理想ですね。
自然言語処理のテキスト生成の技術は、コンピュータとの会話を可能にする夢のある技術ですが、ヒトのレベルに達するのはまだまだ先の話かもしれません。

